PANDAS
Manipulate data like a pro with Pandas
Pull up a chair and make yourself comfortable as Mihalis Tsoukalos explains how to use Pandas for storing and manipulating tabular data.
Credit: https://pandas.pydata.org
OUR EXPERT
Mihalis Tsoukalos is a systems engineer and a technical writer. He’s also the author of Go Systems Programming and Mastering Go, 2nd edition.
QUICK TIPS
Anaconda creates a controlled environment that enables you to define the version of Python as well as the versions of the packages you want to use. It’s available as an Individual Edition for solo user, students and researchers.
P
andas is a Python library that gives you a rich set of tools to carry out data analysis. It’s no exaggeration to say that if you’re going to work with Machine Learning and Data Analysis in Python, then you need to learn how to use Pandas, which excels at data conversions, selections and manipulations using simple to understand code.
The core elements of Pandas are the DataFrame and Series structures, which are used for data storage because without data you have nothing to process, explore or work with. The Series structure is a onedimensional labelled array that can hold any kind of data, whereas the DataFrame structure is a twodimensional and size-mutable data structure. Before we see these two data structures in action, we need to learn how to install Pandas.
Installing Pandas
Although you can install Pandas on its own, the recommended way is under the Anaconda environment. Installing Anaconda (https://anaconda.org) on an Arch Linux system is as simple as running the pacman -S anaconda command with root privileges – use your favourite package manager for installing Anaconda on your own Linux system. You can operate Anaconda using the conda command line utility once Anaconda is activated. You can activate Anaconda on Arch Linux by running source /opt/anaconda/bin/activate root . After that, your Linux shell prompt will most likely change to inform you about the active Anaconda environment.
$ conda list pandas # packages in environment at /home/mtsouk/.conda/ envs/LXFormat: # # Name Version Build Channel pandas 1.2.3 pypi_0 pypi
Once Anaconda is installed, you should have Pandas, NumPy, SciPy and Matplotlib installed as well (if not, install them using the conda utility). You can make sure that Pandas is installed by running Should you wish to see the complete list of installed packages, run conda list instead.
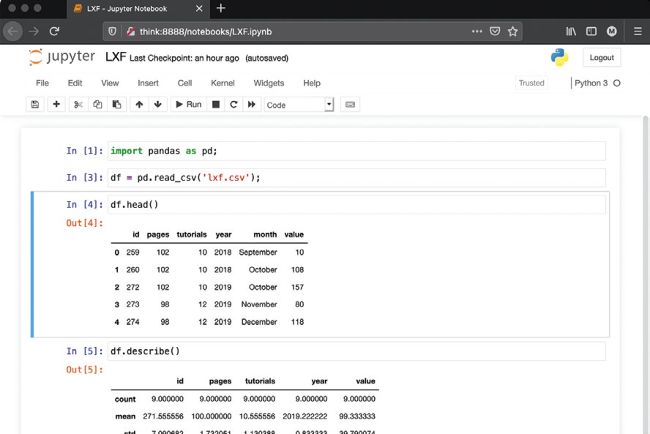
This screenshot shows how to load data from a disk file and learn more about it using the read_csv(), head(), describe() and info() Pandas functions in the Jupyter GUI.
If you don’t want to install Anaconda, you can install Pandas using pip – in that case you should execute pip install pandas with root privileges and run pip show pandas to learn more about the current Pandas installation. You should also do the same for installing NumPy, SciPy and Matplotlib. The following interaction with the Python shell makes sure that Pandas is working: >>> import pandas as pd; >>> print(pd.__version__); 1.2.3